PTWA: Identifikace dalších technologií
Autor: .cCuMiNn. | 2.8.2016 |
Tento text je součástí on-line testovací příručky, která pro vás na tomto serveru vzniká. Budeme rádi za vaše připomínky v komentářích a za vaši aktivní účast v doprovodných projektech.

V tuto chvíli již máme poměrně dost informací o cílovém systému, na kterém se nachází webová aplikace, jíž budeme testovat. Dalším sběrem informací můžeme naše vědomosti o cíli ale ještě více rozšířit. Následující odstavce Vás provedou několika dalšími kroky.
Identifikace webových rozhraní
Na serveru může běžet množství dalších služeb s webovým rozhraním. Ty slouží například pro správu webového serveru (například Apache Tomcat Manager, správce iPlanet, nebo panel pro správu VPS cPanel), či pro správu databází v grafickém režimu (sem spadají například aplikace phpMyAdmin, nebo Adminer). Setkat se můžete také s webovým rozhraním pro správu souborů, nebo elektronické pošty. Tyto aplikace mohou běžet na jiných portech, doménách, subdoménách, či cestách v URL. O enumeraci webových aplikací na serveru budeme sice hovořit až v následující části knihy věnované mapování webové aplikace, ale již na tomto místě stručně zmíním alespoň některé základní informace, jak můžete tato webová rozhraní odhalit.
Vzhledem k tomu, že většina služeb bude dostupná na defaultních umístěních, která jsou pro danou službu typická, měli byste v tuto chvíli zahrnout pokus o návštěvu všech známých lokací na základě slovníku. Doporučuji Vám například použití nástroje DirBuster a slovníků z projektu FuzzDB.
Existují také speciální skripty pro Nmap, které Vám podají informaci o dostupnosti dané služby (například http-webdav-scan), nebo dohledají množství podrobnějších informací (například mysql-info nebo ms-sql-info).
Identifikace naslouchajících služeb
Se skenováním portů, sběrem bannerů a s rozpoznáním naslouchajících služeb na základě komunikace s nimi jste se seznámili již v kapitole věnované identifikaci operačního systému. K průzkumu jste přitom použili nástroje Nmap a Amap.
Není mým záměrem zde předchozí text znovu opakovat. V této kapitole bych ale rád rozšířil význam zjištěných skutečností. Znalost běžících služeb totiž testerovi neslouží pouze k identifikaci běžícího operačního systému, ale může mu poskytnout také další zajímavé informace o použitém databázovém systému, nebo o rozhraní, pomocí kterého dochází k uploadu aplikace na server (FTP, SSH, apd.).
Mimo to je pro testera důležité identifikovat všechny běžící služby z toho důvodu, aby v nich dokázal identifikovat veřejně známé zranitelnosti, ke kterým je případně možné dohledat i odpovídající exploity. O tomto tématu bude ještě řeč později v této části knihy.
Ověření autentizačních údajů
Ve chvíli, kdy se Vám podaří identifikovat webová administrační rozhraní a ostatní běžící služby, bude Vaším úkolem pokusit se k těmto službám přihlásit. K tomu využijte defaultních přístupových údajů, které zjistíte na stránkách výrobce konkrétního produktu, nebo ve veřejně dostupných databázích přístupových údajů. Takovou databází je například ta na webu cirt.net, přičemž se často jedná o kombinaci admin:admin.
Vyzkoušet byste měli i takové kombinace autentizačních údajů, které se často používají v testovacím prostředí, například test:test apd. Pro defaultní účty, u nichž bylo změněno heslo, byste se měli pokusit také o slovníkový útok s nejčastěji používanými hesly, nebo hesly, které se nějakým způsob vztahují k provozovateli testovaného serveru, či aplikace.
K tomuto účelu se Vám bude hodit vynikající nástroj THC-Hydra, který je k dispozici jednak pro příkazovou řádku, ale pro i GUI. Tento nástroj je skvělým řešením pro slovníkové útoky a útoky hrubou silou, které budou detailně rozebrány v kapitole věnované autentizaci a guessingu. THC-Hydra umožňuje testovat platnost autentizačních údajů na velkém množství protokolů a služeb, viz následující tabulka.
| Podporované cíle v nástroji THC-Hydra ve verzi 8.1 | ||||
|---|---|---|---|---|
| Asterisk | HTTP-HEAD | MS-SQL | RDP | SOCKS5 |
| AFP | HTTP-PROXY | MYSQL | Rexec | SSH v1 |
| Cisco AAA | HTTPS-FORM-GET | NCP | Rlogin | SSH v2 |
| Cisco auth | HTTPS-FORM-POST | NNTP | Rsh | Subversion |
| Cisco enable | HTTPS-GET | Oracle Listener | S7-300 | Teamspeak (TS2) |
| CVS | HTTPS-HEAD | Oracle SID | SAP/R3 | Telnet |
| Firebird | HTTPS-PROXY | Oracle | SIP | VMware-Auth |
| FTP | ICQ | PC-Anywhere | SMB | VNC |
| HTTP-FORM-GET | IMAP | PCNFS | SMTP | XMPP |
| HTTP-FORM-POST | IRC | POP3 | SMTP Enum | |
| HTTP-GET | LDAP | POSTGRES | SNMP | |
Při testování současně ověřte, zda se během přihlašovaní k cílovým službám přenáší autentizační údaje zabezpečeným (šifrovaným) kanálem, nebo zda jsou hesla přenášena po síti ve formě plaintextu a je tak možné je na síti odposlechnout. V případě, že by tomu tak bylo, jednalo by se o slabinu, kterou je nutné uvést ve Vaší závěrečné zprávě.
Identifikace Load balancerů, proxy, WAF
Téma rozkládání zátěže, CDN sítí nebo cachování výrazně přesahuje rámec této knihy. Z toho důvodu budu v této kapitole mnoho věcí výrazně zjednodušovat a uvádět pouze takové skutečnosti, které jsou nezbytné pro pochopení důležitosti rozpoznání těchto síťových prvků.
Rozkládání zátěže
Load balancery, aneb zařízení pro vyrovnávání zátěže, slouží v infrastruktuře k tomu, aby posílali návštěvníky aplikace na různé webové servery ve skupině (například dle jejich aktuálního vytížení, nebo podle požadovaného obsahu). Důvodem pro jejich nasazení může být vysoká návštěvnost služby, kdy by již jeden server nestačil na vyřízení požadavků všech uživatelů. Provozovatel aplikace má v takovém případě na výběr ze dvou variant řešení. Buďto navýší výkon daného serveru, nebo rozdělí zátěž na více serverů s nižším výkonem. Použití více slabších serverů je přitom mnohdy levnější variantou. Druhá zásadní výhoda rozdělení zátěže se projeví ve chvíli výpadku některého ze serverů, kdy požadavky uživatelů mohou vyřizovat zbývající stroje. Pokud se ale přidají tyto další servery, je nutné zajistit, aby nějaký nástroj přepojoval uživatele mezi těmito servery. A to je právě úkol load balancerů.
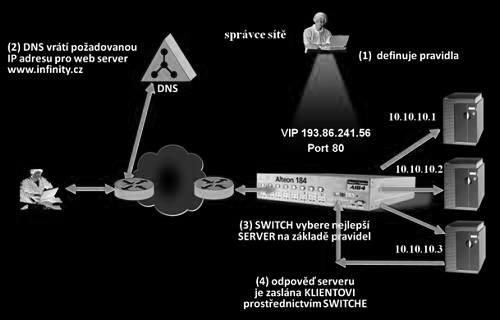
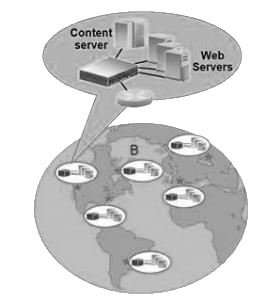
Rozdělování zátěže můžeme rozčlenit do dvou různých skupin, kde první skupinou bude rozkládání trafiku mezi jednotlivé serverové farmy, které jsou od sebe geograficky oddělené. V tomto případě půjde o Global Server Load Balancing (GLSB).
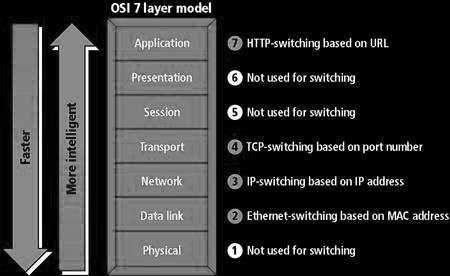
Druhou skupinu tvoří load balancery, které vhodně rozdělí zátěž v rámci jedné serverové farmy. Zde se o tuto funkčnost postarají například SLB switche, které fungují na 2,3,4 a 7 vrstvě OSI modelu.
Z pohledu testera je dobré o přítomnosti load balancerů vědět. Ne na všech serverech, nebo farmách totiž musí běžet stejné verze webové aplikace, čí webového serveru a ne všechny servery musí být nakonfigurované zcela shodně. Pro testera je tedy výhodné, pokud load balancing odhalí a dokáže následně testovat konkrétní servery. Předejde tím například špatně reprodukovatelným chybám, kdy se mu sice podaří vyvolat nějakou chybu, ale při opakování postupu se mu to již znovu nedaří.
V případě použití load balancerů by se dalo říci, že je potřeba otestovat konfiguraci a testovanou aplikaci na všech serverech. Je zřejmé, že toto by ale bylo časově velice náročné. Ideálním řešením je v takovém případě vytváření automatických testovacích skriptů, které následně můžete postupně spustit proti všem cílům za load balancerem. V této části se podíváme na to, jak load balancing odhalit a jak během testu zajistit, že budete přistupovat vždy ke stejnému cílovému systému.
Identifikace load balanceru
V případě Global Server Load Balancingu (GLSB) nás budou zajímat hlavně DNS záznamy typu A k testované doméně. Ty můžete vypsat nástrojem nslookup nebo dig. V případě, že pro testovanou doménu existuje více áčkových DNS záznamů, jedná se o adresy, mezi které je rozdělována zátěž.
Server: 8.8.8.8
Address: 8.8.8.8#53
Name: www.google.cz Address: 173.194.116.247
Name: www.google.cz Address: 173.194.116.248
Name: www.google.cz Address: 173.194.116.255
Name: www.google.cz Address: 173.194.116.239
Složitější situace pro Vás nastane ve chvíli, kdy se budete snažit identifikovat SLB switche, jež rozdělují zátěž v rámci serverové farmy. Zde, jak bylo již uvedeno, může jít balancing na různých vrstvách ISO modelu. My se v našem výkladu zaměříme na L7 switche. Pod L7 switchem si můžete představit zařízení, které vidí obsah HTTP komunikace a na základě jejího obsahu směrují jednotlivé requesty. Je důležité si uvědomit, že v případě, kdy uživatelé komunikují s cílovým systémem šifrovaným kanálem přes HTTPS, pak ani SLB switch není schopen číst obsah této šifrované komunikace. V případě SSL switchů pracujících na sedmé vrstvě ISO modelu proto nemůže být komunikace ukončena až na cílovém serveru, ale již na jemu předřazeném SSL akcelerátoru, za kterým teprve dochází k rozdělování zátěže.
Mnoho aplikací, které s uživatelem navazují a udržují relaci (například po přihlášení uživatele), vyžaduje, aby uživatel během trvání této relace přistupoval vždy ke stejnému serveru za load balancerem. SLB switche proto identifikují uživatele na základě určitých hodnot, například SID relace, které je přenášeno v hodnotě HTTP hlavičky Cookie, a uživatele směřují vždy na stejný stroj ve farmě. Tato skutečnost se Vám bude identifikovat poměrně obtížně. Naštěstí pro Vás ale mnoho SLB switchů přidává do HTTP komunikace také své vlastní cookie, kterým uživateli přiřadí konkrétní server. Některá jména cookies, která jsou load balancery používána najdete v následující tabulce.
| Názvy cookies, které přidavají některé load balancery | |
|---|---|
| Load balancer | Název cookie |
| Apache (mod_proxy_balancer) | ROUTEID |
| F5 BigIP | BIGipServer[pool] =[IP].[port].0000 |
| HAProxy | SERVERID |
Mimo předávání identifikátoru konkrétního serveru v hodnotě cookie se můžete setkat také s jeho předáváním v parametru URL. Příklad takového odkazu, kterým SLB switch instruujete, kterému webovému serveru má Váš požadavek předat, vypadá například takto:
Z důvodu lepšího ladění případných chyb, přidává nezanedbatelné procento webových serverů v serverové farmě svůj identifikátor také do HTML hlaviček, nebo do komentářů ve zdrojovém HTML kódu stránky, například „served by web7“. Při odhalování load balancerů proto nezapomínejte na důkladný průzkum také v této oblasti.
Pojďme nyní ale identifikovat přítomnost load balanceru trochu jiným přístupem. Během zkoumání HTTP hlaviček v odpovědích serverů jste si již možná povšimli hlaviček Date, Last-Modified nebo Expires, které pro náš průzkum mohou být rovněž užitečné. Hlavička Date například obsahuje časovou značku, kdy došlo k vygenerování stránky na straně serveru. Pokud se bavíme o vyrovnávání zátěže, bude pro nás zajímavé porovnat případné odchylky v časech, které obdržíme prostřednictvím hlavičky Date v odpovědích na naše requesty. Pokud totiž naše požadavky bude obhospodařovat více než jeden server a čas na všech zúčastněných serverech nebude dokonale synchronizován, pak je možné, že obdržíte novější čas u response, kterou jste obdrželi dříve. Případně se bude čas rozcházet o větší časový úsek, než jaký uběhl mezi Vašimi requesty. Toto chování je jasným příznakem použití load balanceru. Hlavičky Last-Modified nebo Expires zase informují o tom, kdy byla stránka vygenerována, respektive kdy má vypršet její platnost v cachovacích zařízeních. Předpokládám, že není potřeba dodávat, že na všech serverech za load balancerem bude obsah těchto hlaviček pro stejnou stránku rozdílný.
Posledním způsobem, který na tomto místě zmíním, bude průzkum TCP komunikace. Pokud totiž budete komunikovat se servery za load balancerem a ten Vás bude pokaždé přepínat na jiný server, pak se může stát, že se bude rozcházet hodnota TTL, nebo budou na přeskáčku uvedeny hodnoty id packetu. Většina operačních systémů totiž postupně zvyšuje hodnotu id v odpovědích o určitý přírůstek. Pokud se v odpovědích zobrazí packety s id na přeskáčku, pak lze opět snadno vyvodit závěr, že komunikujeme s více než jedním serverem. Následující výpis, který k vyvolání komunikace využívá nástroj Nping, jež je součástí Nmapu, uvádí příklad, ve kterém id odhaluje přepínání mezi dvěma servery. Oba servery pravděpodobně běží na Windows, pro který je typický jednotkový přírůstek. Druhým nástrojem s obdobnou funkčností, který byste mohli s úspěchem rovněž použít, je hping.
Svou pozornost v uvedeném výpise můžete soustředit i na hodnotu TTL, která může být rozdílná v případě, že byste byli přesměrováváni na servery, které jsou od Vás vzdáleny různý počet hopů. Ve většině případů, ale SLB switch komunikaci přerušuje a započíná novou, díky čemuž obdržíme stále stejné hodnoty i v případě, kdy komunikujeme s různými systémy.
RCVD (0.9300s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=2407 iplen=44 seq=3098212040
RCVD (1.9290s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=2408 iplen=44 seq=3098478363
RCVD (2.9350s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=4287 iplen=44 seq=3098762840
RCVD (3.9290s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=2410 iplen=44 seq=3099031191
RCVD (4.9280s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=4288 iplen=44 seq=3099318290
RCVD (5.9310s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=2412 iplen=44 seq=3099586482
RCVD (6.9310s) TCP 93.185.104.29:80 > 192.168.2.104:1517 SA ttl=114 id=2413 iplen=44 seq=3099852368
Nyní, když víte, jak můžete použití nástrojů pro rozdělování zátěže manuálně identifikovat, pojďme si představit také nějaké nástroje, které tuto identifikaci provedou zcela automaticky. Takovým nástrojem, který Vám na základě uvedených informací přítomnost load balanceru identifikuje a často současně provede i enumeraci jednotlivých serverů je například halbert, nebo ldb.
Přímý přístup k serveru za load balancerem
Pokud budete chtít testovat jeden konkrétní server, bude záležet na tom, zda je tento server přímo přístupný z internetu přes jeho veřejnou IP adresu, nebo zda je dostupný pouze přes load balancer, který k němu přistupuje do vnitřní sítě.
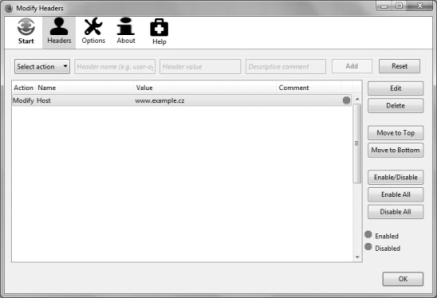
Je-li server přímo dostupný přes jeho IP adresu, budete mít pravděpodobně problém, pokud tuto IP vložíte přímo do adresního řádku prohlížeče. Může se totiž stát, že Vám bude zobrazen jiný obsah, než který jste požadovali, nebo budete přesměrováni na jiné konkrétní doménové jméno, které je na serveru nastaveno jako defaultní. Toto chování způsobuje chybějící hlavička Host, která serveru nepředá informaci o tom, kterou doménu se snažíte načíst. Hlavičku Host můžete ale do komunikace přidávat explicitně a serveru tak sdělovat, o kterou doménu máte zájem. Přidání této hlavičky Vám zajistí například vhodný doplněk webového prohlížeče. Osobně s úspěchem používám doplněk pro Firefox, který se jmenuje Modify Headers.
Druhá možnost, kterou máte k dispozici, je vložit záznam s provázáním domény na konkrétní IP adresu do svého souboru hosts. V Linuxu tento soubor najdete v adresáři /etc, ve Windows ve složce C:\Windows\System32\drivers\etc. Zápisem do tohoto souboru zajistíte, že při přístupu k testované doméně se nebudete dotazovat DNS serveru na IP adresu, která by mohla v případě rozložení zátěže přicházet v závislosti na čase odlišná. Při požadavku se Váš systém totiž nejprve podívá do souboru hosts a pokud tam najde odpovídající záznam, odešle Váš HTTP request přímo na uvedenou IP adresu.
V případě, že ke konkrétnímu serveru nemůžete přistupovat přímo skrze jeho IP adresu, například protože se server nachází v serverové farmě, kde jednotlivé servery mají přidělenu pouze lokální IP adresu, bude nutné nejprve zjistit, zda existuje nějaká hodnota v požadavku, která by Vám umožnila konkrétní server, ke kterému hodláte přistoupit, specifikovat.
Jak již bylo uvedeno v dříve textu, vkládají tato zařízení do komunikace často URL parametry nebo cookies, na základě kterých se rozhodují, na který server Váš požadavek předají. Pokud tento údaj v komunikaci odhalíte, máte vyhráno, protože jej snadno přepíšete požadovanou hodnotou.
Proxy servery, cache
Mezi další prvky, které mohou ovlivnit Vaši komunikaci se serverem a určují, jaký obsah Vám bude na Váš požadavek vrácen, patří proxy servery cachující obsah. Tato zařízení se do infrastruktury zapojují, aby se snížily požadavky na objem přenášených dat a snížila se doba odezvy. Funguje to tak, že pokud si od aplikace vyžádáte určitá data, ta při přenosu zpět k Vám mohou být uložena ve vyrovnávacích pamětech těchto zařízení. Při Vašem příštím požadavku (nebo při požadavku jiného uživatele) na stejný zdroj dat, pak na Váš požadavek odpoví některé ze zařízení, které má tento obsah ve své cache uložen.
Díky tomu nebude muset aplikace znovu obsluhovat Váš požadavek, a data se nebudou muset přenášet celou trasou. Největší úspory se tak dočkáte v případě, že se proxy server s vyrovnávací pamětí nachází přímo ve Vaší lokální síti. Jak je asi patrné, je vhodné využívat cache pouze pro statický obsah (obrázky, fonty, css, javascript, zvuky nebo videa). Naopak pro dynamicky generovaný obsah, kdy aplikace na opakované zaslání stejného požadavku reaguje pokaždé odlišným obsahem, se tato zařízení nehodí a situaci mohou poměrně výrazně komplikovat.
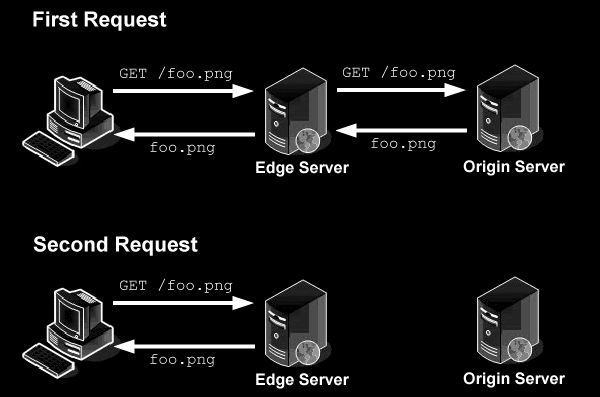
Během testování byste proto měli mít o různých cachovacích zařízeních na cestě alespoň nějakou představu. Důrazně Vám také doporučuji nepoužívat během testování proxy server, který můžete mít ve Vaší síťové infrastruktuře zařazen právě z důvodu cachování. Při jeho využití během testu totiž nemusíte vždy komunikovat přímo s cílovým systémem. Odpovědi Vám může zasílat právě tento proxy a z toho důvodu nemusí být reakce zcela relevantní. Proxy servery se často konfigurují také tak, aby filtrovaly určitý nepovolený obsah. I v tomto případě může být Vaše testování nelibě ovlivněno.
Skutečnost, zda konkrétní obsah může být cachován na síťových prvcích, nebo v lokální cache webového prohlížeče, sděluje aplikace prostřednictvím HTTP hlavičky Cache-Control. Do procesu řízení cachování mohou ale vstupovat také hlavičky Pragma, Expires, Last-Modified nebo ETag. Průzkum nastavení těchto hlaviček bude podrobně popsán později. Svou úlohu při cachování hrají i různé meta tagy, kterými se ale naštěstí řídí pouze prohlížečová cache.
Problematice cachování se budeme více věnovat při popisu útoků na cache (cache Poisoning), během kterých útočník otráví obsah v cache s cílem zobrazit uživateli jiný obsah, než který vrací webová aplikace. O cachování bude řeč ale také v souvislosti s ukládáním citlivých údajů.
Identifikace aplikačních firewallů
Další skutečnost, která Vás bude během testů určitě zajímat, je přítomnost aplikačního firewallu. Aplikační firewally nasazené do prostředí pro ochranu webových aplikací se označují výrazem web application firewall (WAF) a správci je nasazují proto, aby pomocí nich vyfiltrovali nebezpečné vstupy, které se útočníci snaží aplikaci podstrčit ke zpracování. Díky tomu mohou být i aplikace, které nedostatečně validují vstupy, nebo trpí jinými zranitelnostmi, uchráněny před případnými útoky. Většina aplikačních firewallů pracuje na základě seznamu pravidel, které jsou definovány pomocí regulárních výrazů a v komunikaci se snaží odhalit jim odpovídající sekvence. Ne všechna pravidla jsou ovšem dokonalá, a pokud je testerovi známa přítomnost WAF, případně i jeho verze, pak se může pokusit tato pravidla vhodnou úpravou svých vstupů obejít.
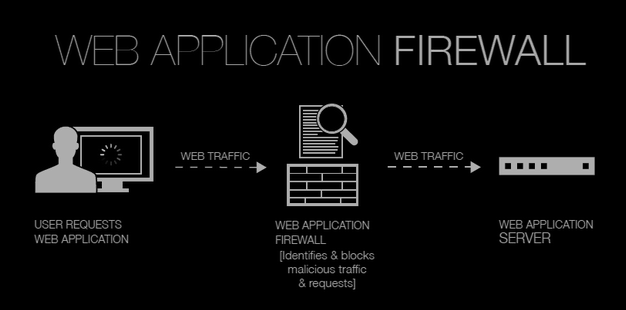
Otázkou zůstává, jak přítomnost tohoto bezpečnostního nástroje detekovat. Dříve, než se seznámíme s automatizovanými nástroji pro detekci WAF, zaměříme se na signatury, které za sebou v komunikaci WAF zanechávají a na možnosti jejich manuální identifikace.
První, co byste měli během pátrání po WAF provést, bude opět detailní průzkum HTTP hlaviček a cookies. Mnoho aplikačních firewallů za sebou zanechává v komunikaci otisk v podobě jejich názvů. Následující tabulky uvádí příklady některých aplikačních firewallů a defaultních názvů cookies nebo HTTP hlaviček, které jsou pro daný produkt typické.
| Souvislost mezi názvem cookie a nasazeným WAF | |
|---|---|
| Cookie | Web Application Firewall |
| ns_af | Citrix Netscaler |
| barra_counter_session | Barracuda |
| AL_SESS, AL_LB | Airlock |
| NCI__SessionId | NetContinuum |
| st8id | Teros |
| WODSESSION | Hyperguard |
| Souvislost mezi HTTP hlavičkou a nasazeným WAF | |
|---|---|
| HTTP hlavička | Web Application Firewall |
| X-Varnish | Varnish FireWall |
| X-dotDefender-denied | dotDefender |
| nnCoection , Cneonction | netScaler |
| X-Cnection | BIG-IP |
| Server: BinarySec | BinarySEC |
| Server: F5-TrafficShield | F5 TrafficShield |
| HTTP/1.1 999 No Hacking | WebKnight |
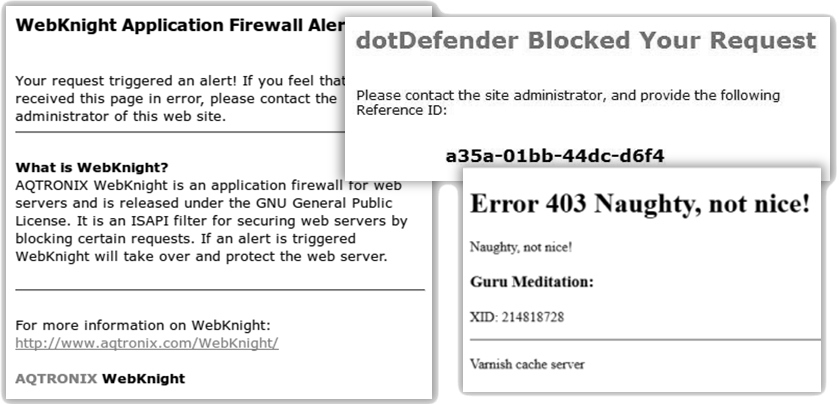
Některé aplikační firewally se projevují také tím, že velice rychle uzavírají otevřené HTTP spojení, nebo je blokování závadného obsahu doprovázeno chybovou stránkou vygenerovanou aplikačním firewallem, jak ukazuje následující obrázek.
Nyní, když víme, na základě jakých indicií je možné aplikační firewall detekovat, pojďme se podívat na některé automatické nástroje, které na základě několika požadavků dokáží nasazený WAF odhalit a rozpoznat. K tomuto účelu můžeme využít například skript http-waf-detect z nám již dobře známého scanneru Nmap. Tento skript bohužel pokrývá pouze malé spektrum aplikačních firewallů a my tak budeme muset sáhnout i po nějakém jiném specializovaném nástroji. Mezi ty lze zařadit například WAFw00f, WAFtester, ParadoxWAFDT, IronBee WAF Research, Pyronbee, případně nástroj se kterým se podrobně seznámíme v kapitolách věnovaných SQL injekci sqlmap. Ten má detekci WAF implementovánu pod přepínačem --identify-waf.
Budeme potěšeni, pokud vás zaujme také reklamní nabídka
.Přihlášení | ||
.Infobox Nejnovější:
Články:
BugTrack: HackForum: Další služby: Na SOOM.cz je:
Článků: 991
Komentářů: 14 257 Aktualit: 1 862 Souborů: 151 WebForum: 49 482 Hardware: 38 Diskuze: 20 617 BugTrack: 4 415 Reg. uživatelů: 16 353 A proběhlo:
Zobraz. článků: 17 976 558
Staženo souborů: 1 401 549 Staženo dat: 902 987 MB Přístupy (hits): 225 592 680 | ||
| ||||
| |||
| |||

| |||

| ||||
| ||||
| ||||
| ||||
| ||||||||||||||||||||||||