PTWA: Identifikace webového serveru
Autor: .cCuMiNn. | 13.7.2016 |
Tento text je součástí on-line testovací příručky, která pro vás na tomto serveru vzniká. Budeme rádi za vaše připomínky v komentářích a za vaši aktivní účast v doprovodných projektech.

Další v řadě, kdo čeká na Vaší identifikaci, je po operačním systému webový server. I u něj byste měli správně určit, o jaký typ serveru se jedná a ideálně také to, která jeho verze před Vámi běží. Jedině tak budete v případě, že administrátoři správně a včasně neupdatují, schopni vyhledat veškeré zranitelnosti a odpovídající exploity, které můžete na konkrétním webovém serveru aplikovat.
Informace, zda se jedná o Apache, Apache Tomcat, nebo například o IIS, Vám navíc později napomůže také při identifikaci jazyka, který byl použit při vývoji aplikace. Umožní Vám ale i snazší dohledávání různých konfiguračních rozhraní a usměrní Vaše kroky při vyhledávání zranitelností v samotné webové aplikaci.
HTTP response hlavičky
Podobně, jako tomu bylo u identifikace operačního systému, také v případě webového serveru můžete často k jeho identifikaci využít HTTP response hlavičky, kterými server mnohdy bezostyšně sděluje veřejnosti svou identitu a dokonce i číslo své verze. Stačí, když na server odešlete jediný požadavek, například přistoupíte na homepage webu, a v nástroji Burp Suite si prohlédnete vrácenou odpověď. Pokud v ní naleznete HTTP hlavičku Server, dobře si prohlédněte její hodnotu, zda neuvádí konkrétní verzi běžícího webového serveru.
Práci s nástroji Netcat a Burp Suite jsme si již popsali dříve při identifikaci operačního systému na základě HTTP response hlaviček. Rozpoznání webového serveru tímto způsobem probíhá naprosto identicky, a není tedy potřeba na tomto místě konkrétní postupy opakovat.
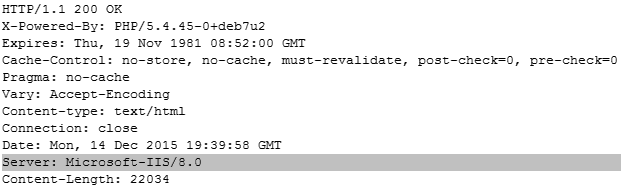
I v tomto případě ale platí, že hodnota HTTP hlavičky Server mohla být záměrně změněna správcem serveru tak, aby obsahovala nepravdivou informaci a tím mátla případného útočníka. Hodnotě uvedené v této hlavičce tedy raději příliš nevěřte, a i v případě, že je obsažena, proveďte pro jistotu také testování popsané na následujících stránkách, čímž si pravdivost zjištěného údaje ověříte.
Pořadí HTTP response hlaviček
Pokud chcete blíže specifikovat webový server bez toho, že byste se spoléhali čistě jen na vrácenou HTTP hlavičku Server, můžete se blíže zaměřit na některou z odpovědí. Webové servery mají například tu vlastnost, že vrací HTTP response hlavičky v různém pořadí, podle toho o jaký server se jedná. RFC26161, které je protokolu HTTP věnováno, totiž webovým serverům přímo nenařizuje, v jakém pořadí mají být tyto hlavičky v odpovědi uvedeny. Díky této skutečnosti tak můžete webový server alespoň zhruba úspěšně identifikovat.
V následujících třech výpisech si všimněte skutečnosti, že webový server Apache používá ve svých odpovědích opačné pořadí HTTP hlaviček Date a Server, nebo Content-Length a Content-Type, než například IIS nebo nginx.
- HEAD / HTTP/1.0
- HTTP/1.1 200 OK
- Date: Mon, 30 May 2016 16:02:25 GMT
- Server: Apache/2.4.12
- Vary: Accept-Encoding,User-Agent
- Content-Length: 0
- Connection: close
- Content-Type: text/html
- HEAD / HTTP/1.0
- HTTP/1.1 200 OK
- Content-Length: 0
- Content-Type: text/html; charset=utf-8
- Vary: Accept-Encoding
- Server: Microsoft-IIS/8.5
- Date: Mon, 30 May 2016 16:05:09 GMT
- Connection: close
- HEAD / HTTP/1.0
- HTTP/1.1 200 OK
- Server: nginx
- Date: Mon, 30 May 2016 16:13:22 GMT
- Content-Type: text/html; charset=utf-8
- Connection: close
- Vary: Accept-Encoding
- Content-Length: 13025
Odpověď na nepodporovanou verzi HTTP
Stejně, jako se různé webové servery staví různě k pořadí vrácených HTTP hlaviček, staví se různě také k tomu, jakou odpověď zvolí ve chvíli, kdy po nich vyžadujete komunikaci nepodporovanou verzí HTTP protokolu (konkrétně například HTTP 3.0). Následující výpisy opět zachycují odpovědi dvou různých serverů.
- HEAD / HTTP/3.0
- HTTP/1.1 200 OK
- Date: Mon, 30 May 2016 16:26:30 GMT
- Server: Apache/2.4.12
- Content-Length: 0
- Connection: close
- Content-Type: text/html
- HEAD / HTTP/3.0
- HTTP/1.1 505 HTTP Version Not Supported
- Content-Length: 350
- Content-Type: text/html; charset=us-ascii
- Server: Microsoft-HTTPAPI/2.0
- Date: Mon, 30 May 2016 16:21:02 GMT
- Connection: close
Použití nepodporovaného protokolu
Zajímavé je také to, jak se chovají různé webové servery v případě požadavků, které uvádí nepodporovaný protokol, například JUNG namísto HTTP. Nikoho z vás v tuto chvíli již zřejmě nepřekvapí, že i tentokrát se budou vrácené odpovědi diametrálně rozcházet.
- GET / JUNG/1.0
- HTTP/1.1 200 OK
- Date: Mon, 30 May 2016 16:26:30 GMT
- Server: Apache/2.4.12
- Content-Length: 234
- Connection: close
- Content-Type: text/html
- GET / JUNK/1.0
- HTTP/1.1 400 Bad Request
- Server: Microsoft-IIS/5.0
- Date: Fri, 01 Jan 1999 20:14:34 GMT
- Content-Type: text/html
- Content-Length: 87
- GET / JUNK/1.0
- <HTML><HEAD><TITLE>Bad request</TITLE></HEAD>
- <BODY><H1>Bad request</H1>
- Your browser sent a query this server could not understand.
- </BODY></HTML>
Použití zakázaných HTTP metod
Ani při použití zakázaných HTTP metod nedrží webové servery stejný krok. Ve chvíli, kdy na homepage webu odešleme DELETE požadavek, bude nám toto odepřeno různými odpověďmi.
- DELETE / HTTP/1.0
- HTTP/1.1 405 Method Not Allowed
- Date: Sun, 15 Jun 2003 17:11:37 GMT
- Server: Apache/1.3.23
- Allow: GET, HEAD, POST, PUT, DELETE, CONNECT, OPTIONS, PATCH, PROPFIND, PROPPATCH,
- MKCOL, COPY, MOVE, LOCK, UNLOCK, TRACE
- Connection: close
- Content-Type: text/html;
- charset=iso-8859-1
- DELETE / HTTP/1.0
- HTTP/1.1 403 Forbidden
- Server: Microsoft-IIS/5.0
- Date: Fri, 01 Jan 1999 20:13:57 GMT
- Content-Type: text/html
- Content-Length: 3184
- DELETE / HTTP/1.0
- HTTP/1.1 401 Unauthorized
- Server: Netscape-Enterprise/4.1
- Date: Mon, 16 Jun 2003 06:03:18 GMT
- WWW-authenticate: Basic realm="WebServer Server"
- Content-length: 223
- Content-type: text/html
- Connection: close
GET požadavky s různou délkou
Když si vše shrneme do přehledné tabulky, která ukazuje odpovědi jednotlivých serverů, zjistíte, že identifikovat verzi použitého webového serveru není skutečně nijak zvlášť složité.
| Shrnutí popsaných informací | ||||
|---|---|---|---|---|
| Server | Řazení | Verze | Protokol | Metoda |
| Apache | Date, Server | 400 | 200 | 405 |
| Microsoft-IIS | Server, Date | 200 | 400 | 403 |
| Netscape-Enterprise | Server, Date | 505 | no header | 401 |
Ve Vašem snažení ale můžete zajít ještě dále. Můžete se zaměřit například i na to, jak se konkrétní servery staví k běžným GET požadavkům se specifickou délkou požadované URL adresy. Také při tomto testování se budou webové servery chovat k Vašim požadavkům rozdílně.
| Odpověď některých serverů na různě dlouhý GET požadavek | ||
|---|---|---|
| Server | Délka URL | Reakce serveru |
| Apache 1.3.12 | 1 - 216 | 404 Not Found |
| 217 - 8176 | 403 Forbidden | |
| 8177 a více | 414 Request-URI Too Large | |
| Netscape-FastTrack 4.1 | 1 - 4089 | 404 Not found |
| 4090 - 8123 | 500 Server Error | |
| 8124 - 8176 | 413 Request Entity Too Large | |
| 8177 a více | 400 Bad request | |
| Microsoft IIS | 1 - 260 | 404 Not Found |
| 261 - 16382 | 400 Bad request | |
| 16383 a více | 414 Request-URI Too Large | |
Otestovat můžete také vložení HTTP hlavičky, jejíž hodnota bude určité velikosti. Následující tabulka shrnuje reakci několika serverů, kdy jste ve svém requestu použili některou nadměrně dlouhou HTTP hlavičku.
| Závislost reakce serveru na velikosti HTTP hlaviček | |||
|---|---|---|---|
| Server | Velikost hlavičky | Status | Zdroj stránky |
| Apache 2.4.4 | 8109 (hlavička+hodnota) | 400 | <h2>Bad Request - Request Too Long |
| Microsoft IIS 6.0 | 16330 (všechny hlavičky) | 400 | <h1>Bad Request (Request Header Too Long |
| Microsoft IIS 8.5 | 16330 (všechny hlavičky) | 400 | <h2>Bad Request - Request Too Long |
V případě webového serveru Apache Vám doporučuji vložit dlouhou hodnotu do hlavičky Cookie. Stává se totiž, že Apache uvede ve vrácené chybové zprávě také obsah všech cookies včetně těch, které jsou chráněny příznakem HttpOnly. Obsah této stránky včetně chráněných cookies by pak bylo možné přečíst a odeslat útočníkovi pomocí zranitelnosti Cross-Site Scripting, které se budeme později důkladně věnovat.

NULL char v URL
Vložení bílého znaku %00 do cesty v URL je další variantou, která Vám umožní rozpoznat webový server. Následující tabulka zobrazuje reakce několika typů webových serverů na odeslání požadavku http://www.example.cz/%00
| Odpověď některých serverů na request se znakem NULL v URL | ||
|---|---|---|
| Server | Reakce serveru | |
| Apache | Not Found The requested URL / was not found on this server. | |
| Microsoft IIS 6.0 | Bad Request (Invalid URL) | |
| Microsoft IIS 7.5, 8.5 | Bad Request - Invalid URL HTTP Error 400. The request URL is invalid. | |
| Apache-Coyote 1.1 | Prázdná stránka | |
| Nginx | 400 Bad Request nginx | |
Další rozdíly v implementaci HTTP
Poslední rozdíl v implementaci různých webových serverů, který na tomto místě zmíním, bude souviset s vložením řetězce mezi HTTP request hlavičky bez použití dvojtečky, která běžně slouží pro oddělení HTTP hlavičky od její hodnoty. Pokud tedy na server odešlete request, který bude takový řádek obsahovat, viz následující výpis, pravděpodobně se dočkáte chybové stránky se stavovým kódem 400. Obsah této stránky je pak závislý na nasazeném webovém serveru.
- GET / HTTP/1.1
- Host: www.example.cz
- test
- Connection: close
| Odpověď některých serverů na request s nevalidní hlavičkou | |
|---|---|
| Server | Reakce serveru |
| Apache | Bad Request Your browser send a request that this server could not understand. Request header field is missing ":" separator. |
| Microsoft IIS 6.0 | Bad Request (Invalid Header Name) |
| Microsoft IIS 7.5, 8.5 | Bad Request - Invalid Header HTTP Error 400. The request has an invalid header name. |
| Oracle HTTP server | The request contains invalid syntax. |
| Lotus Domino | Http Status Code: 400 Reason: Request contains an HTTP header that doee not contain a colon |
Výše uvedenými skutečnostmi výčet rozdílů v chování jednotlivých webových serverů ale rozhodně nekončí. Zkuste se například pomocí nástroje Netcat připojit k několika webovým serverům a zkuste jim posílat různé neočekávané vstupy. Zjistíte, že podle jejich odezvy budete poměrně rychle schopni rozeznat, zda na druhé straně naslouchá Apache, IIS, nebo něco jiného.
Automatický fingerprinting webserveru
Protože existuje velká spousta různých verzí webových serverů, těžko byste byli schopni identifikovat veškeré rozdíly v jejich chování včetně správného přiřazení verze jen manuálním osaháním cílového systému. Určitě Vám proto přijde vhod nějaký automatický nástroj, který tuto činnost vykoná za Vás a na základě signatur se pokusí přiřadit správnou verzi běžícího serveru.
httprint
Asi nejznámějším nástrojem tohoto druhu je httprint. Tento nástroj odešle na cílový server zhruba 20 různých requestů a na základě vrácených odpovědí vytvoří signaturu cílového systému, kterou následně porovná s interní databází signatur známých webových serverů.
Httprint je k dispozici ve verzi pro příkazovou řádku pro operační systémy Linux, Mac OS X, FreeBSD a Windows. Windows verze je ale k dispozici také v GUI provedení.
Při práci s tímto nástrojem v jeho grafické podobě pro Vás budou důležité dva textové soubory. Prvním z nich je soubor pojmenovaný input.txt, od kterého httprint očekává, že bude obsahovat seznam IP adres, nebo doménových jmen serverů, které si přejete otestovat. Druhým souborem je pak signatures.txt, který obsahuje databázi signatur známých serverů, proti které bude prováděno porovnání.
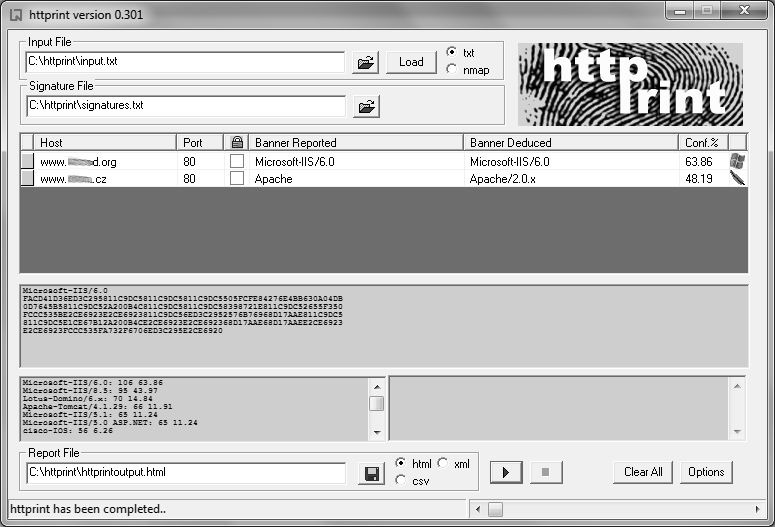
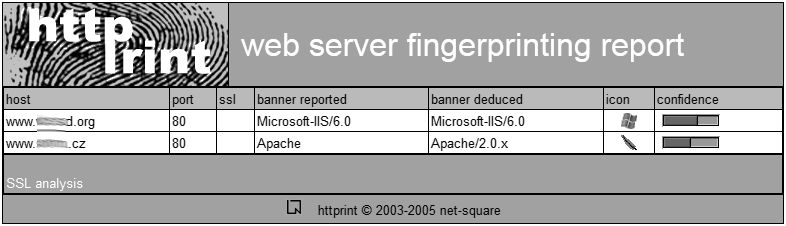
Asi největší nevýhodou nástroje httprint je jeho zastará databáze signatur. Poslední přírůstky byly přidány naposledy v roce 2005. Webové servery od té doby ale prošly poměrně velkým vývojem a na verze, které má httprint ve své databázi, tak už na internetu nejspíš vůbec nenarazíte. Pokud Vám stačí, když Vám tento nástroj zařadí webový server alespoň druhově, pak bude jistě výtečným pomocníkem. Nečekejte ale, že si jej stáhnete a on Vám bude schopen okamžitě identifikovat všechny aktuální verze testovaných serverů. I tak ale nemusíte zoufat. Přestože není k dispozici aktuální databáze signatur, nic Vám nebrání vytvořit si svou vlastní sbírku. Httprint obsahuje signatury v již zmíněném textovém souboru signatures.txt, do kterého můžete velice snadno přidávat své vlastní záznamy. Vždy, když otestujete nějaký nový server, u kterého budete vědět, jaká verze je na něm použita, jednoduše překopírujete signaturu tohoto systému z výstupu httprint do uvedeného souboru, a při příštím testování bude Váš vzorek již použit při porovnání společně s ostatními signaturami.
httprecon
Druhým nástrojem pro fingerprinting webových serverů je nástroj Marca Ruefa httprecon. Podobně jako httprint odesílá i tento nástroj na webový server sadu speciálně připravených HTTP requestů a z odpovědí se snaží určit, s jakým webovým serverem komunikuje. Zmíněna sada obsahuje celkem devět typů požadavků, které zahrnují testy z následujícího obrázku. Obrázek zachycuje také sadu atributů, které jsou brány na vědomí během vytváření signatury.
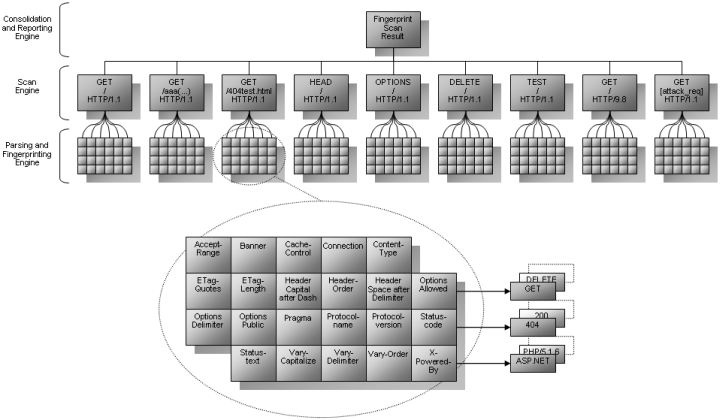
Nástroj httprecon je sice k dispozici pouze v GUI verzi pro Windows, ale ani majitelé ostatních systémů nepřijdou zkrátka, pokud budou chtít funkcionality tohoto nástroje využívat. Organizace w3dt, která si správu tohoto projektu vzala pod patronát, nabízí na svém webu on-line verzi tohoto nástroje, který tak může bez potíží využít opravdu každý.
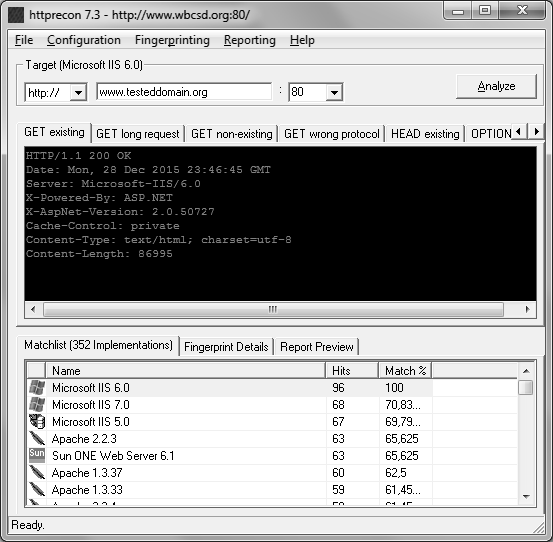
Doplňky do webových prohlížečů
Existuje také celá řada různých doplňků do webového prohlížeče, z nichž zmíním například vynikající nástroj Wappalyzer od Elberta Aliase. Ten je k dispozici pro prohlížeč Firefox, nebo pro Google Chrome, a při návštěvě webové stránky Vám zobrazí informace o operačním systému, webovém serveru a dalších technologiích, které webová aplikace využívá. Bohužel se v určení webového serveru řídí tyto nástroje hlavně hodnotami v HTTP hlavičkách, které, jak již víme, mohou podávat nepravdivé údaje. Na druhou stranu, pokud je možné webovému serveru věřit, umožní Vám získat poměrně rychle značný přehled o použitých technologiích. Jednotlivé ikony těchto technologií se Vám přehledně zobrazí v adresním řádku webového prohlížeče, a po jejich rozkliknutí doplní i další údaje, jako jsou například konkrétní použité verze. Nástroj Wappalyzer se nesoustředí pouze na HTTP hlavičky. S využitím regulárních výrazů se v nich sice snaží vyhledávat konkrétní řetězce, ale vedle nich se soustředí také na cookies a dokonce i na samotný obsah HTML stránek. Díky tomu jsou výsledky poskytnuté tímto nástrojem poměrně přesné. Za návštěvu stojí také návštěva webových stránek projektu, kde jsou k dispozici zajímavé statistiky.
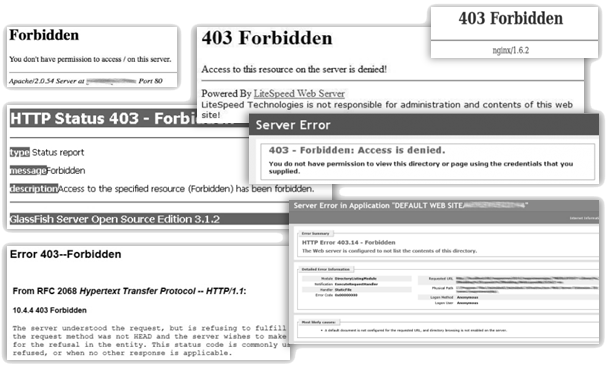
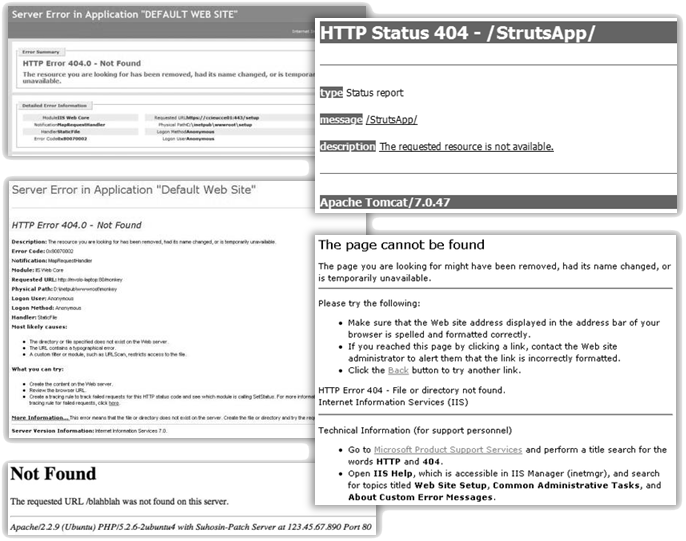
Defaultní chybové stránky
O defaultních chybových stránkách byla již také řeč dříve při identifikaci operačního systému, kde jsem současně uváděl i některé metody, jak chybové stránky poměrně jednoduše vyvolat.
Pokud se Vám podaří vyvolat defaultní chybové stránky serveru, máte, co se identifikace webového serveru týče, téměř vyhráno. Ačkoliv operační systém prozrazují tyto stránky ve svých patičkách pouze někdy, verzi webového serveru nám sdělí poměrně často.
V případech, kdy chybová stránka neobsahuje konkrétní informaci o běžícím serveru, dá se z formátu chybové stránky přesto poměrně snadno odhadnout, o jaký typ serveru se jedná. Následující koláže screenshotů chybových stránek se stavovými kódy 403, 404 a 500 zachycují odlišný vzhled těchto defaultních stánek poskytnutý různými typy a verzemi webových serverů. Na mnoha z těchto screenshotů si můžete všimnout také zveřejněné informace o konkrétní verzi běžícího serveru.
Bohužel mohou být i v případě defaultních chybových stránek informace o použitém webovém serveru úmyslně pozměněny. Nezapomínejte proto vždy ověřovat pravdivost zjištěných informací i dalšími metodami, které jsou uvedeny v této kapitole.

Defaultní uvítací stránka serveru
Informaci o běžícím webovém serveru Vám může poskytnout také defaultní uvítací (testovací) webová stránka serveru, která je k dispozici ihned po instalaci webového serveru. Pokud je v konfiguraci serveru nastaven explicitně pouze root adresář pro každého z vhostů, ale defaultní root adresář je ponechán v implicitním nastavení, není často problém se k této defaultní uvítací stránce dostat. Mnohdy stačí, když si přeložíte doménové jméno testované aplikace na IP adresu a prohlížečem navštívíte získanou IP adresu napřímo. V požadavku také někdy stačí změnit obsah hlavičky host, aby tato obsahovala hodnotu, pro kterou nebude na serveru nalezen odpovídající vhost. Pokud má server jako vhost nakonfigurovány pouze konkrétní subdomény, ale v DNS záznamech je uvedeno, že se mají na daný server směřovat požadavky všech subdomén, postačí také pouze vypustit z adresy doménu třetího řádu, nebo na jejím místě uvést neexistující hodnotu.

Jak si můžete všimnout na obrázku výše, identifikovat na základě defaultní uvítací stránky typ a verzi běžícího webserveru není příliš velkým problémem.
Speciální názvy složek a souborů
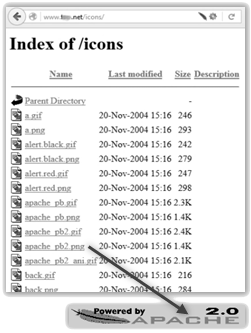
V případě webového serveru Apache přichází do úvahy ještě další způsob jeho identifikace. Tato metoda spoléhá na to, že má Apache často nakonfigurované aliasy, které směřují do některých jeho složek na filesystému. Asi nejčastěji je dostupný alias pro adresář icons, který Vám po zadání tohoto adresáře do cesty v URL zobrazí ikony dostupné tomuto webovému serveru, viz obrázek.
Logo Apache, které je v této složce dostupné pod souborem pojmenovaným apache_pb2.png dokonce upřesňuje konkrétní verzi serveru. Porovnání velikosti jednotlivých souborů umístěných v této složce s databází jednotlivých verzí Apache pak také dokáže poskytnout informaci o přesné verzi běžícího serveru.
Mezi další aliasy a moduly, které byste měli určitě vyzkoušet, patří ty z následující tabulky. Abyste se vyhnuli možným problémům s parsováním URL, ukončujte cestu v URL lomítkem, např. http://www.example.cz/htdocs/
| Aliasy, které mohou být dostupné na serveru Apache | |
|---|---|
| Adresář | Soubor |
| bin | bin/php.ini |
| cgi-bin | cgi-bin/printenv.pl |
| conf | conf/httpd.conf |
| error | error/contact.html.var |
| doc | |
| docs | |
| htdocs | htdocs/index.html |
| icons | icons/apache_pb2.gif |
| include | include/os.h |
| lib | lib/xml.lib |
| log | |
| logs | logs/access.log |
| manual | manual/index.html |
| modules | modules/mod_version.so |
| server-status | |
| status | |
| stats | |
| statistics | |
Pokud pokus o přístup ke složce vrací status kód 403 Forbidden, sděluje Vám tím server, že požadovaná složka existuje, a Vy si tak můžeme být téměř jisti, že je testovaným webovým serverem Apache. Ve chvíli, kdy je zakázán výpis složky, můžete se také pokusit načíst některý ze souborů, který v konkrétní složce bývá běžně umístěn. Příklady těchto souborů najdete rovněž v předchozí tabulce.
Webový server Apache je dále možné rozpoznat díky jeho defaultnímu nastavení, ve kterém brání v přístupu k souborům začínajícím na .ht. Toto odepření přístupu zavádí Apache z toho důvodu, aby uživatelé nemohli přistupovat a číst obsah souborů .htaccess a .htpasswd. Pokud se tedy během identifikace pokusíte načíst například tuto adresu http://www.example.cz/.ht a bude Vám vrácena chybová stránka se stavovým kódem 403 (odepření přístupu), pak před Vámi stojí s největší pravděpodobností opět právě Apache. Když už budete u tohoto testu, vyzkoušejte rovnou načíst přímo soubor .htaccess, respektive .htpasswd. Pokud existuje a webový server je špatně nakonfigurován, mohlo by se Vám podařit zobrazit jeho obsah.
Mezi další soubory, jejichž existence může prozradit použitý webový server, nebo i jazyk, ve kterém je aplikace vytvořena, patří například ty, které uvádí následující tabulka. Výskyt těchto souborů byste proto měli rovněž prověřit, přičemž práci Vám značně usnadní nástroje jako je DirBuster, o kterém se podrobněji zmíním například ve spojitosti s hledáním přípon souborů v kapitole Identifikace jazyka a frameworku. Možnost čtení obsahu těchto souborů by byla poměrně závažnou chybou nastavení webového serveru, protože Vám může poskytnout mnoho cenných informací o konfiguraci cílového systému, nebo dokonce prozradí různé autentizační údaje. Seznam dalších souborů a jejich umístění, které náleží MS technologiím, si můžete prohlédnout přímo na webových stránkách Microsoftu.
| Soubory, jejichž výskyt je možný ve spojitosti určitými technologiemi | |
|---|---|
| Soubor | Technologie |
| web.config | ASP.NET |
| global.asa(x) | ASP |
| service.cnf | Microsoft IIS |
| .htaccess, .htpasswd | Apache |
| phpinfo.php, info.php | PHP |
| apc.php | PHP |
Budeme potěšeni, pokud vás zaujme také reklamní nabídka
.Přihlášení | ||
.Infobox Nejnovější:
Články:
BugTrack: HackForum: Další služby: Na SOOM.cz je:
Článků: 991
Komentářů: 14 257 Aktualit: 1 862 Souborů: 151 WebForum: 49 484 Hardware: 38 Diskuze: 20 617 BugTrack: 4 415 Reg. uživatelů: 16 355 A proběhlo:
Zobraz. článků: 17 985 137
Staženo souborů: 1 402 683 Staženo dat: 903 664 MB Přístupy (hits): 226 058 413 | ||
| ||||
| |||
| |||

| |||

| ||||
| ||||
| ||||
| ||||
| ||||||||||||||||||||||||