Programování spiderů v Pythonu 2 - Download, Mechanize a formuláře
Zdroj: SOOM.cz [ISSN 1804-7270]Autor: Jakub Tětek
Datum: 16.3.2014
Hodnocení/Hlasovalo: 1.56/9
Dnes si ukážeme, jak stahovat soubory, které jsou sekvenčně uloženy pod ID. V druhé části vám ukáži, jak vyplňovat formuláře pomocí Mechanize, knihovny, kterou budeme po zbytek seriálu používat pro interakci s webem.
Stahování souborů se sekvenčními ID
 Soubory jsou často na webu ukládány pod sekvenčními jmény. To znamená, že soubory mají jména v nějakém rozsahu. Například je ve složce sto souborů, které se jmenují 1 až 100. To budeme demonstrovat na příkladu s Google mapami, kde se budeme zabývat satelitními snímky.
Soubory jsou často na webu ukládány pod sekvenčními jmény. To znamená, že soubory mají jména v nějakém rozsahu. Například je ve složce sto souborů, které se jmenují 1 až 100. To budeme demonstrovat na příkladu s Google mapami, kde se budeme zabývat satelitními snímky.
Půjdeme tedy na adresu staré verze map. Je důležité si uvědomit, že mapa se skládá z dlaždic. Dlaždice je obrázek o rozměrech 256x256 pixelů ve formátu JPEG. My potřebujeme zjistit, jak stáhnout obrázky, z kterých se skládá mapa. Pokud se podíváme na HTML kód stránky, tak zjistíme, že Google mapy používají hodně JavaScriptu, ze kterého není jednoduché vyčíst, odkud se dlaždice stahují. Proto si nainstalujeme doplněk prohlížeče Web Developer bar (Google Chrome, Firefox), díky kterému budeme moci zobrazit seznam všech obrázků, které jsou aktuálně načteny.
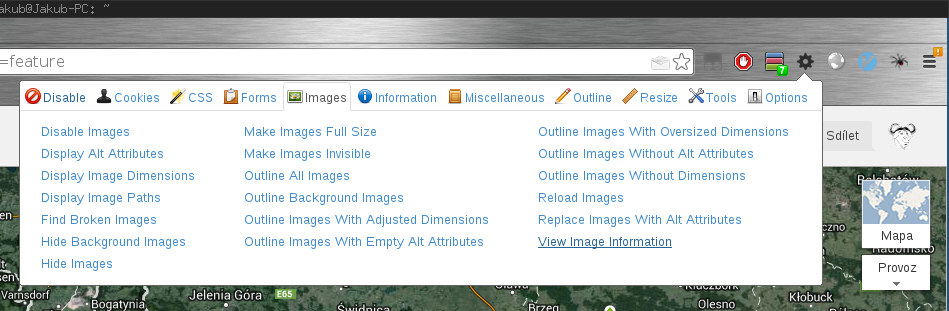
Otevřeme Web Developer toolbar. V kategorii Images se vpravo dole nachází volba View Image Information. Když na ní klikneme, tak se v nové záložce otevře seznam všech načtených obrázků. V seznamu můžeme najít i dlaždice mapy a to včetně odkazu na jejich URL adresu.
Adresa může vypadat například takto:
https://khms0.google.com/kh/v=145&src=app&x=136&y=86&z=8&s=Galile
Jak vidíte, mimo jiné se metodou GET posílají i proměnné x a y. Pokud hodnotu některé z nich zvýšíte či snížíte o jedna, zobrazí se vám sousední dlaždice. Takto bychom mohli stáhnout dlaždice v nějakém rozsahu a pak je jen pospojovat. To lze udělat například tímto Bash skriptem:
#!/bin/bash
#./downloadmap.sh x_od x_do y_od y_do z
# příklad: ./downloadmap.sh 132 137 85 88 8
# posledním parametrem je proměnná „z“, neboli zoom. Neexistují ovšem všechny souřadnice x a y pod všemi úrovněmi přiblížení (1-20)
for i in $(eval echo {$1..$2}); do
for j in $(eval echo {$3..$4}); do
curl -L -o "$i-$j.jpg" "https://khms1.google.com/kh/v=135&x=$i&y=$j&z=$5"
done
convert $(eval echo $i-{$3..$4}).jpg -append $i.jpg
done
convert $(eval echo {$1..$2}).png +append out.jpgTento skript bohužel poběží pouze na Linuxu a OS X (a možná v Cygwinu), pokud ho tedy chcete používat na Windows, budete si ho muset přepsat do jiného jazyka.
Pokud tento skript plánujete používat, tak si dejte pozor, aby jste nebyli Googlem zablokováni kvůli přílišnému počtu požadavků.
Beztrestně si tuto techniku můžete vyzkoušet například na webu It-Ebooks.info. Ne vždy jsou ale ID sekvenční. Jako příklad uvedu službu reCAPTCHA od Googlu.
Mechanize
Mechanize je Pythonovská knihovna usnadňující interakci s webem. Svým fungováním je velmi podobná Perlovské WWW:Mechanize, odkud také pochází velká část zdrojových kódů. Mechanize nám umožní operovat s objektem prohlížeče, který je podobný prohlížeči klasickému, ve kterém teď pravděpodobně čtete tento článek, ale není grafický a ovládá se programově. Můžeme tak jednoduše vyplňovat formuláře, vracet se v historii prohlížení, používat cookies a podobně.
Nainstalujte Mechanize příkazem
# pip install mechanizePokud nemáte Pip, nainstalujte ho příkazem
# apt-get install pipTento příkaz bude fungovat pouze na distribucích používajících apt. Na ostatních Linuxových distribucích se tento příkaz bude lišit podle používaného package-managera.
Pro novější verze Pythonu (3.x) je bohužel dostupná pouze experimentální verze. Vývoj Mechanize už byl ale bohužel ukončen a knihovna tak zastarává.
Registrace
Abychom si patřičně ukázali možnosti Mechanize, naprogramujeme bota, který se za nás zaregistruje na Facebooku. Zatím sice nebude umět potvrdit registrační email, ale na to se podíváme v příštím dílu této série.
Jako první budeme muset vytvořit instanci Mechanize prohlížeče.
import mechanize
br = mechanize.Browser()Každá doména by měla mít ve svém kořenovém adresáři soubor robots.txt, který mimojiné sděluje, zda je botům povoleno, či zakázáno přistupovat na konkrétní stránky. Facebook robotům přístup zakazuje. Zákaz založený na bázi souboru robots.txt je ale pouze informační, tzn. že stránka říká, že tam nesmíme. Ovšem to, zda robot toto sdělení uposlechne, nebo jej bude ignorovat, je pouze v jeho režii. Prohlížeč Mechanize je defaultně nastaven tak, aby se souborem robots.txt řídil. Bude proto potřeba toto chování změnit, což lze udělat následujícím řádkem.
br.set_handle_robots(False)Poté v prohlížeči programově otevřeme stránku https://www.facebook.com/
br.open('https://www.facebook.com/')Nyní přichází na řadu to zajímavé. Je potřeba vyplnit a odeslat registrační formulář. Formulář je skupina vstupních polí, které k sobě patří a odesílají se všechny najednou. Formulářů může být na stránce více a je tak nutné prohlížeči sdělit, který má z nich chceme vyplňovat. Pokud se podíváte do HTML kódu a vyhledáte oba formuláře nacházející se na stránce, zjistíte, že registrační formulář je v HTML uveden jako druhý v pořadí. Protože se ale formuláře počítají od nuly (tudíž přihlašovací formulář není první, ale vlastně nultý), tak potřebujeme vybrat formulář číslo jedna.
br.select_form(nr=1)Následuje vyplnění vstupních polí. Každé z nich má své, v rámci formuláře, unikátní jméno. Abychom mohli pole vyplnit, je dobré tato jména znát. V Google Chrome je můžeme zjistit tak, že klikneme na každé ze vstupních polí pravým tlačítkem a z nabídky vybereme volbu Inspect Element. Zobrazí se okno, ve kterém bude vidět hezky zformátovaný HTML kód. Kód vstupního pole, na které jsme klikli přitom bude označený. V označené části kódu tedy vyhledáme, jakou hodnotu má vlastnost name. Tuto hodnotu následně použijeme při automatickém vyplňování.
Následující příklad nastaví vstupní pole pojmenované „firstname“ na hodnotu „Jakub“.br.form['firstname'] = 'Jakub'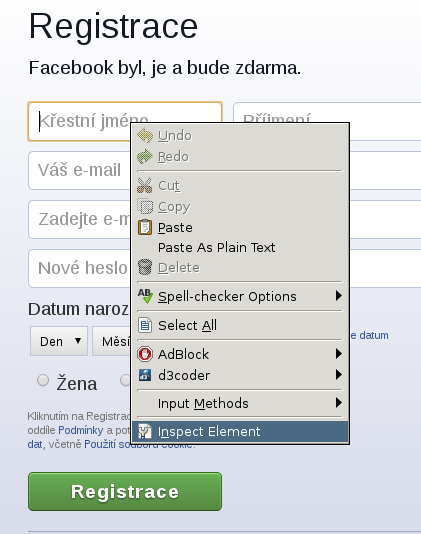
Hodnotu u výčtových typů formuářových elementů, mezi které patří například radio button nebo select nastavíme na list (česky seznam) obsahující hodnotu value konkrétní volby, kterou chcete vybrat.
HTML kód formuláře může obsahovat například takovýto výčtový prvek select:
Pokud bychom z tohoto seznamu chtěli programově vybrat měsíc březen, musíme hodnotu výběru nastavit na ['3']. Hranaté závorky jsou použity proto, že jde o seznam. Apostrofy proto, že hodnota musí být předána jako string.
Pokud tento postup zopakujeme pro všechny vstupní pole, která je potřeba vyplnit a dáme to dohromady se zbytkem, tak bychom mohli dostat něco takovéhoto:
import mechanize
from random import randint
def registerFacebook(firstname, surname, sex, mail, passwd):
br = mechanize.Browser() # vytvorime si objekt Mechanize prohlizece
br.set_handle_robots(False) # nastavime, aby ignoroval soubor "robots.txt"
br.open('https://www.facebook.com/') # otevreme stranku Facebooku
br.select_form(nr=1) # vybereme, ze bydeme vyplnovat prvni formular
# vyplnime formular
br.form['firstname'] = firstname
br.form['lastname'] = surname
br.form['reg_email__'] = mail
br.form['reg_email_confirmation__'] = mail
br.form['reg_passwd__'] = passwd
# vybereme nahodne volby
br.form['birthday_day'] = [str(randint(1,28))]
br.form['birthday_month'] = [str(randint(1,12))]
br.form['birthday_year'] = [str(randint(1960,1995))]
br.form['sex'] = [str(sex)]
req = br.submit() # odesleme formular
print(req.read()) # vypiseme HTML kod stranky, co prisla v odpovediNakonec už jen funkci zavoláme s požadovanými paramatr. Hodnotu „sex“ ve volání nastavíme na 1 pokud chceme zvolit pohlaví „Žena“, 2 pokud chceme zvolit možnost „Muž“.
registerFacebook('jmeno', 'prijmeni', 2, 'nekdo@nekde.tld', 'heslo')Funkce vypisuje odpověď serveru, kterou si přesměrujeme do souboru, se kterým můžeme dále pracovat v prohlížeči.
$ python registerFacebook.py > file.html
$ chromium file.htmlTěmito příkazy otevřete odpověď na vaši registraci v prohlížeči Chromium. Odpovědí je typicky stránka žádající o potvrzení emailu.
Příště budeme programově odesílat e-maily a automaticky tak ověříme email v naší registraci.