Captcha Seznamu prolomena
Autor: Emkei | 7.6.2011 |
Jako cíl jednoho ze svých seminárních projektů jsem si zvolil prolomení captcha ochrany u české internetové jedničky Seznam.cz. Jelikož jsem se nezaměřil pouze na tuto společnost, ale i obecné principy OCR a na něm založené útoky, vznikl tento, dle mého názoru zajímavý článek plný praktických zkušeností a ukázek.

![]() Než se pustíme do samotného prolamování captcha, rád bych v krátkosti upřesnil, na jakém principu vlastně dokáže OCR software jednotlivá písmena v obrázcích rozeznávat. Jako každé zjednodušené nastínění funkcionality, i to moje se v zájmu snazšího pochopení dopustí jistých nepřesností. Samotné OCR je sofistikovaná technika využívající spousty algoritmů pro rozpoznávání symbolů jako je detekce ok a hran, já popíši pouze jeden, který ovšem krásně demonstruje principy fungování této technologie. Každé písmeno je unikátní svým tvarem, jak ovšem počítač dokáže tyto tvary reprezentované jedničkami a nulami rozlišovat? Zjednodušeně, u každého písmene si vytvoří horizontální a vertikální histogram a tento pár porovná se svojí databází. Histogram si můžeme představit jako "setřepání" pixelů buď horizontálním, nebo vertikálním směrem, lépe nám tuto metodu představí následující obrázky reprezentující písmeno A a jeho histogramy.
Než se pustíme do samotného prolamování captcha, rád bych v krátkosti upřesnil, na jakém principu vlastně dokáže OCR software jednotlivá písmena v obrázcích rozeznávat. Jako každé zjednodušené nastínění funkcionality, i to moje se v zájmu snazšího pochopení dopustí jistých nepřesností. Samotné OCR je sofistikovaná technika využívající spousty algoritmů pro rozpoznávání symbolů jako je detekce ok a hran, já popíši pouze jeden, který ovšem krásně demonstruje principy fungování této technologie. Každé písmeno je unikátní svým tvarem, jak ovšem počítač dokáže tyto tvary reprezentované jedničkami a nulami rozlišovat? Zjednodušeně, u každého písmene si vytvoří horizontální a vertikální histogram a tento pár porovná se svojí databází. Histogram si můžeme představit jako "setřepání" pixelů buď horizontálním, nebo vertikálním směrem, lépe nám tuto metodu představí následující obrázky reprezentující písmeno A a jeho histogramy.

Vizuální reprezentace písmene A

Horizontální histogram písmene A

Vertikální histogram písmene A
Pro louskání captcha útočníkům bohatě postačí volně dostupné nástroje, nejsou zapotřebí žádné placené utility. Já s oblibou používám komplexní balík ImageMagick, který dokáže s obrázkem na základě příkazů doslova divy. Pro audio captchu prozměnu oceníte bohaté funkce "švýcarského nože pro zpracování zvukových záznamů" s názvem Sound eXchange (SoX). Ukažme si nyní, jak s ImageMagick pracovat. Příkladem nám budiž již nyní captcha společnosti Seznam.cz, která využívá statické pozadí. Takové pozadí postrádá v obrázku smysl a neposkytuje ani nejmenší náznak dodatečné ochrany. Pozadí captchy odstraníme jednoduše tak, že si vytvoříme pozadí bez písmen (background.gif) a toto poté od louskaných obrázků (captchaImage.gif) odečítáme (difference.gif) a převádíme na kombinaci dvou barev (result.gif). Následuje praktická ukázka:



Captchu Seznamu nenalezneme pouze na registračních formulářích, společnost ji nabízí rovněž formou API ostatním vývojářům. Setkat se s ní tedy můžete na různých fórech, ale i anketách nebo soutěžích. Poznáte ji podle charakteristického mřížového pozadí.
Již na první pohled se captcha dopouští několika školáckých chyb, především:
- statické pozadí
- malá množina písmen [A-N]
- žádná deformace
- velké odsazení jednotlivých písmen
Na druhé straně má i svá pozitiva, která útočníkům komplikují práci, patří mezi ně:
- rotace a změna velikosti písmen
- barva písma splývá s barvou pozadí
- vlastní font písma
Zastavím se ještě u použité množiny písmen. Po několika testech a stažení velkého množství captcha obrázků pro následné učení OCR čtečky se množina použitých písmen rozrostla z [A-N] na [A-Z], přičemž vynecháno bylo pouze písmeno Q. Nevím, zda si někdo ze Seznamu mého počínání všiml nebo se jednalo o pouhou náhodu, každopádně se jednalo o tah správným směrem.
Rovněž jsem uvedl, že Seznam používá vlastní font, tak to malinko rozvedu. Font si nechal vyrobit na zakázku od společnosti Suitcase Type Foundary, a to ve dvou provedeních:
- Seznam Script
- Seznam Text
Vlastní font je v případě tvorby captchy obrovská výhoda. Pro útočníka to totiž ve většině případů znamená, že mu nestačí standardní databáze OCR čtečky, ale bude ji muset naučit sám novým tvarům, což je časově velice náročné, chce-li dosáhnout vysoké úspěšnosti. Pro detekci použitého fontu útočníci ocení služeb webové aplikace WhatTheFont!, ve které lze na základě uploadu obrázku s neznámým fontem nebo popisem jeho charakteristických rysů zjistit, o jaký font se jedná. Pokud to totiž víme, tvorbu vlastní OCR databáze nám to výrazně usnadní a zrychlí.
Jak tedy postupovat konkrétně v případě lámání captchy u společnosti Seznam.cz? Následovně:
Stáhneme si originální obrázek captchy:
Odstraníme statické pozadí. Zda využijete utilitu convert, compare, nástroje GD knihovny nebo úplně něco jiného, záleží zcela na vás:
Převedeme obrázek do dvou barev, typicky černé a bílé:
Metodou Flood Fill (plechovka s barvou) postupně vybarvíme jednotlivá písmena, a to vždy jiným odstínem, abychom následně mohli rozlišit jednotlivé části při segmentaci:

Povedeme segmentaci, tedy oddělení jednotlivých písmen, a vrátíme se k monochromatickým barvám (ty jsou důležité pro OCR čtečku, která příliš světlé barvy, jako je např. žlutá, ignoruje). Problém zde nastává v případech, kdy se některá písmena překrývají. I tyto situace u Seznam API nastávají, dají se ovšem díky špatné implementaci ze strany vývojářů poměrně elegantně vyřešit, viz níže:

Následuje natočení písmen, aby správně "stála". Stejná písmena musejí stát vždy stejně, byť ne třeba z pohledu člověka správně. Toho dosáhneme u latinky poměrně snadno, správně stojící písmena v ní totiž mají obvykle nejmenší šířku. Natočíme proto každé písmeno o 45° v obou směrech a při každém stupni změříme šířku. Nejmenší šířku poté vyhodnotíme jako správné postavení písmene. Takto upravená písmena jsou již připravena pro OCR čtečku:

Součástí každé složitější captchy by měla být funkce pro aktualizaci obrázku. Pokud tomu tak není, jedná se o trestuhodnou implementaci, kterou uživatelé neodpouštějí, uživatelský zážitek se pak totiž stává noční můrou. Seznam touto funkcí disponuje, implementována však byla dost nešťastným způsobem. Po kliknutí na příslušný odkaz pro aktualizaci obrázku se zdá, že vše funguje tak, jak má. Vždy se načte zcela unikátní captcha. Při bližším prozkoumání ovšem zjistíte, že tomu tak zcela není. Nová captcha se získává tak, že se volá script:
Ten na svůj výstup pošle XML soubor obsahující unikátní náhodně vygenerovaný hash pro captchu. Vše vypadá nějak následovně:
Přidělený hash se poté předává scriptu pro generování grafické podoby captcha obrázku:
Dosud se zdá být postup v pořádku, problém nastává až tehdy, kdy script pro generování captchy zavoláme s jedním a tím samým hashem opakovaně. V takovém případě se generuje vždy stejná captcha – se stejným obsahem, písmena pouze mění svá natočení a velikost. Tato chyba se nám hodí v případech, kdy je OCR čtečce předložen obrázek, kde se jednotlivá písmena překrývají. Opětovným voláním výše uvedené URL si můžeme jednoduchým způsobem zažádat o přegenerování captchy a doufat, že nyní se již stejná písmena překrývat nebudou. Opakovat volání scriptu lze u jednoho hashe cca 5 až 40× (nepodařilo se mi vydedukovat, na základě čeho se toto chování řídí), poté je nutné zažádat o nový hash. Kdykoliv se tedy nějaká písmena překrývají, máte jistotu, že v některé další variantě téže captchy se již překrývat nebudou a vy tedy i přesto uspějete.
Jako OCR čtečku jsem zvolil utilitu gocr (respektive jocr, chcete-li). Jedná se o oblíbenou utilitu, která je volně k dispozici a často slouží jako backend jiným aplikacím. Vedle své databáze disponuje tento nástroj možností tvorby vlastní neuronové sítě a její následné učení s učitelem. Kdo se zajímá o umělou inteligenci, bude nadšen.
Pro potřeby vlastního ukázkového PoC jsem si nejprve stáhnul stovky captcha obrázků ze Seznamu, na které jsem aplikoval výše uvedené postupy. Poté jsem jednotlivá písmena (celkem více jak 5 000) ručně roztřídil. Gocr se učí následujícím způsobem:
Čísla za parametrem -m říkají, že se má OCR učit, parametr -p definuje umístění databáze a -i samotného testovaného obrázku. Pravděpodobně vám neuniklo, že jsem si obrázky zkonvertoval pomocí balíků ImageMagick do formátu PNM, se kterým umí OCR lépe pracovat než s tradičními formáty. Gocr se nejprve pokusí písmeno rozeznat sám na základě vnitřní databáze. Pokud se mu to nepodaří, vykreslí písmeno na obrazovku a požádá uživatele, aby k danému obrázku dopsal jeho znakovou reprezentaci, viz níže:
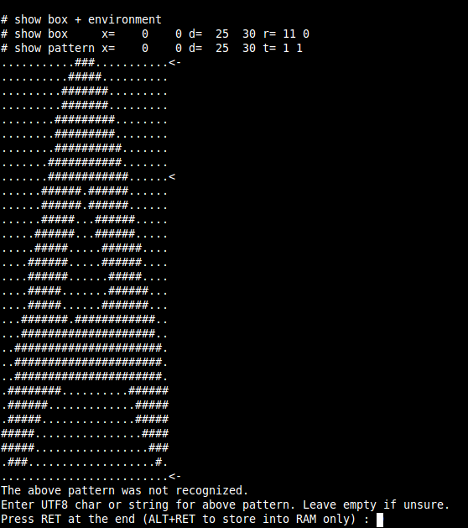
Na nerozpoznané písmeno se gocr zeptá
U takového množství obrázků již samozřejmě při učení pomáhají útočníkům scripty. Nově vytvořená databáze se nám ve výše uvedeném případě uložila do složky ./seznam/. Při ostrém rozpoznávání znaků ji nesmíme zapomenout zmínit, a to následovným způsobem:
Čísla za parametrem -m říkají, že má OCR použít jinou než standardní databázi znalostí, a to tu určenou parametrem -p. Přepínač -u definuje zástupný znak, který se použije v případě, že nebude znak na obrázku rozeznán, přičemž je nastavena hranice jistoty 90 % (-a). Zbývající parametry jsou všeříkající, velké C definuje množinu přípustných znaků a přepínač -i cestu k rozpoznávanému obrázku s textem.
Svůj PoC (ke stažení níže) jsem nejprve napsal v PHP a BASHi. Využil jsem při tom balík ImageMagick a GD knihovnu (pro některé věci se víc hodí jedno, pro jiné to druhé). Pomalost takové aplikace byla ovšem tristní a tak jsem vše přepsal do Perlu. Opět jsem použil ImageMagick (tentokrát formou modulu, nikoliv systémového volání), GD a gocr. Aplikace se výrazně zrychlila, úspěšnost ovšem mírně klesla. Za to pravděpodobně může fakt, že vzorky pro učení OCR byly generovány ještě pomocí staré aplikace psané v PHP a BASHi, zatímco porovnávány již byly se vzorky zpracovávané Perlem. Jako PoC s takřka 100% úspěšností to ovšem bohatě stačí.
 Seznam nyní připravuje novou tvář captchy, která je sice propracovanější, zároveň však i mnohem méně čitelná. Jelikož ale disponuje funkcí pro aktualizaci kódu, není ztížená čitelnost na obtíž a pomineme-li nepochopitelné použití diakritiky u písmen, jedná se opět o krok správným směrem. S novou captchou se můžete již nyní setkat např. na registračním formuláři sociální sítě Lidé.cz.
Seznam nyní připravuje novou tvář captchy, která je sice propracovanější, zároveň však i mnohem méně čitelná. Jelikož ale disponuje funkcí pro aktualizaci kódu, není ztížená čitelnost na obtíž a pomineme-li nepochopitelné použití diakritiky u písmen, jedná se opět o krok správným směrem. S novou captchou se můžete již nyní setkat např. na registračním formuláři sociální sítě Lidé.cz.
Proof of Concept ke stažení zde.
Budeme potěšeni, pokud vás zaujme také reklamní nabídka
.Přihlášení | ||
.Infobox Nejnovější:
Články:
BugTrack: HackForum: Další služby: Na SOOM.cz je:
Článků: 991
Komentářů: 14 263 Aktualit: 1 862 Souborů: 151 WebForum: 49 497 Hardware: 38 Diskuze: 20 629 BugTrack: 4 415 Reg. uživatelů: 16 412 A proběhlo:
Zobraz. článků: 18 154 396
Staženo souborů: 1 460 150 Staženo dat: 961 924 MB Přístupy (hits): 230 431 651 | ||
| ||||
| |||
| |||

| |||

| ||||
| ||||
| ||||
| ||||
| ||||||||||||||||||||||||